Overview
Paragon is composed of multiple microservices running within Kubernetes or Docker. While there are over 30 packages and microservices, the microservices can generally be grouped into two groups:- Configuration
- Execution
Configuration
When you log into Paragon, you can add team members, create workflows, configure steps, add and edit secrets, and more. All of these actions and their data fall under the Configuration category and are persisted in real-time to Postgres. Postgres acts as the source of truth, and when you are editing your configurations, they’re generally immediately persisted into Postgres.Execution
When workflows or connect proxy requests are triggered, they use cached versions of the configurations (e.g. workflows and steps, credentials, etc). Request volumes can be in the tens or hundreds of millions which require reads and writes in the microsecond-millisecond range. Generally, executions rely on cached data in Redis built from configurations stored in Postgres. Logs/results are flushed to Postgres periodically in batches to reduce the load on servers.Datastores
A diagram of where data is stored can be found below.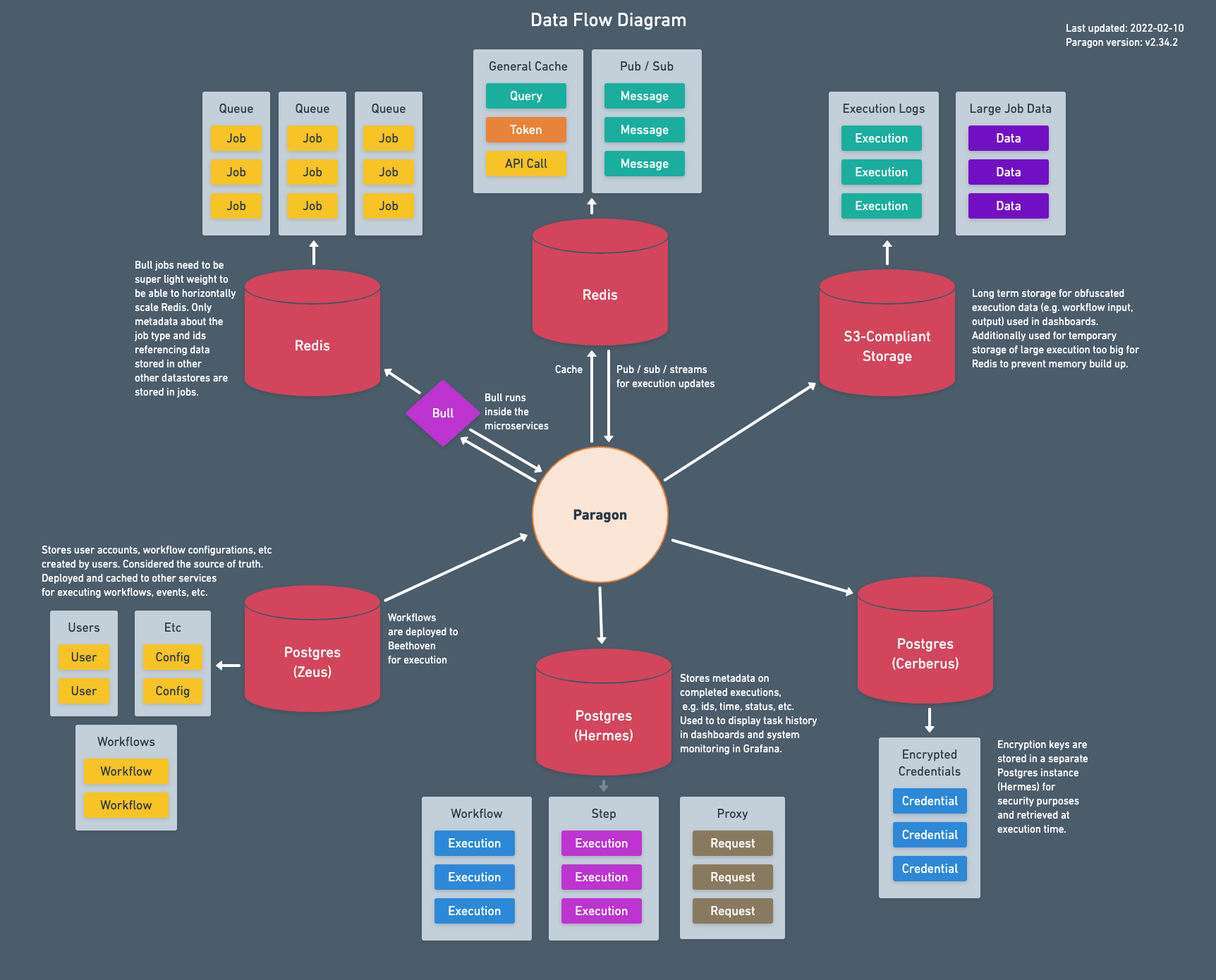
Microservice Communication
Microservices communicate with each other in one of two methods:Requests that fall in the Execution category (e.g. executing live workflows, Connect proxy requests, etc) and may happen in large volumes are queued in Redis as jobs. This allows the services to dynamically scale to meet the volume without losing data, retry failed jobs, and provide metrics on throughput, failure rates, and job metadata.
HTTP-based Communication
Requests that fall in the Configuration category (e.g. editing workflows, adding team members, etc) that usually occur in low volumes are typically handled via HTTP calls over the private network. Custom tooling is used to add retry logic based on response codes, provided distributed tracing, validate payloads, and more.Queuing Retry Logic
Requests that fall in the Execution category (e.g. executing live workflows, Connect proxy requests, etc) have sophisticated logic around retries, some configurable and some automatic.Configurable step retries
Auto-retries can be enabled in the sidebar next to your steps. This will retry steps with jitter and exponential backoff upon failure. This is useful for when rate limits may be hit or other faulty APIs.