Usage
The Permissions API uses the same base URL and authorization details as the Sync API.About Permission Syncs
Permission Syncs use available APIs to query all ways that users can access or inherit access to a file. For example, for the Google Drive integration, Paragon syncs permissions for:- Direct access assigned to files
- Inherited access from parent folders
- Google Group member access (direct or inherited)
- Google Workspace organization-wide access
- If not designated as “searchable by organization”: access granted from an opened link
Query to check if a user has access to File ID
Supported Integrations
The following File Storage integrations support Permissions API (see the links below for any additional OAuth scopes or configuration parameters you may need to include to enable permissions indexing):Implementing Permissions API
To implement Permissions API in a production context, your application will need to query the Permissions API to check for access when documents are being requested. Below is a diagram illustrating how Sync API and Permissions API can be used together in a RAG application (“Your App”) where an organization admin connects their Google Workspace to your app to ingest workspace files on behalf of everyone in that organization. Permissions API can be used to filter documents that match the user’s query from your vector/search database to only the files that the user has access to in Google Workspace.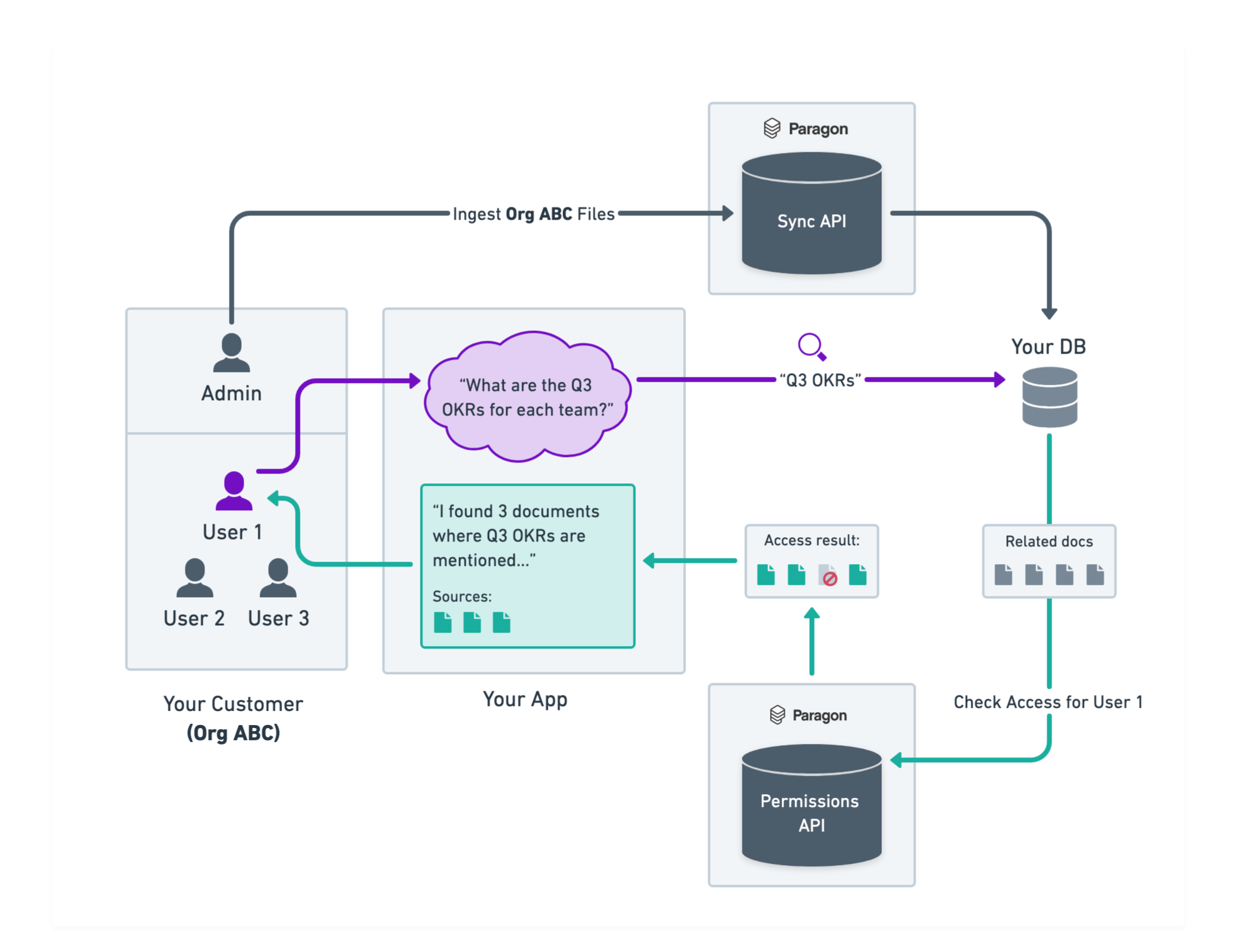
Pre-search Filtering
This approach will only scale to a small corpus of documents (≤ 1000 total).If your users will sync more documents, we recommend using a post-filtering or hybrid approach as described below.
file.id from the File schema) that you can use to limit your search index parameters.
Example in Pinecone
Example in Pinecone
Example in Elasticsearch
Example in Elasticsearch
Post-search Filtering
In post-search filtering, you can use Permissions API to filter the results of your search query to only include documents that the user has access to. After you receive ranked search results from your vector database, send a request to the Batch Check Access endpoint to check if the current user has access to the result documents by passing a list of IDs:allowed property that will tell you if the current user has access to the file (directly or via a transitive relationship).
You can use this list to filter down the search results from your database and include the accessible documents in your LLM context.
We recommend over-fetching by a factor of at least 2x from your search / vector database to account for scenarios where some relevant documents will not be available to the user.
Hybrid Approach
You can combine pre-search and post-search filtering techniques to limit the search space upfront for your database queries while ensuring that permissions enforcement is accurate for document sets of >1000 files. Use coarse-grained pre-search filters to limit the initial search space (removing documents from e.g. different teams or spaces that the user is not assigned to), and use the Permissions API to filter the final results, verifying that the user has access to the documents that are ultimately used in a response. Some examples of coarse pre-search filters you can use:- Folder IDs that the user has access to
- Space/Drive IDs that the user has access to
- Group/Team IDs that the user is a member of
Example in Pinecone
Example in Pinecone
Example in Elasticsearch
Example in Elasticsearch